





Элементы статистики
Понятие о статистике
Статистика — наука, занимающаяся сбором, обработкой и изучением всевозможных данных, связанных с массовыми явлениями, процессами и событиями, носящими преимущественно случайный характер.
Математическая статистика — раздел прикладной математики, посвящённый математическим методам систематизации, обработки и исследования статистических данных для научных и практических целей.
Статистическое наблюдение — это спланированный, научно организованный сбор массовых данных о социально-экономических явлениях и процессах.
Случайными величинами в статистике называют такие величины, которые в ходе наблюдений или испытаний могут принимать различные значения. Можно говорить о том, что их значения зависят от случая.
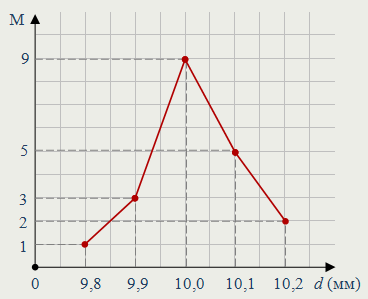
На практике часто после проведения реальных испытаний составляются таблицы распределения значений случайных величин по частотам (или по относительным частотам), после чего для большей наглядности распределение данных представляют либо в виде диаграммы, либо в виде полигона частот (полигона относительных частот).
► Например, имеются результаты 20 измерений диаметра d болта (в миллиметрах с точностью до 0,1):
10,1 10,0 10,2 10,1 9,8 9,9 10,0 10,0 10,2 10,0
10,0 9,9 10,0 10,1 10,0 9,9 10,0 10,1 10,1 10,0
Представим эти данные с помощью: 1) таблицы распределения по частотам M и относительным частотам W; 2) полигона частот.
| 1) Таблица частот и относительных частот | |||||
| d | 9,8 | 9,9 | 10,0 | 10,1 | 10,2 |
| M | 1 | 3 | 9 | 5 | 2 |
| W =
M/N | 0,05 | 0,15 | 0,45 | 0,25 | 0,1 |
Отметим, что сумма всех значений частот (строка значений M) равна N = 20, сумма всех значений относительных частот (строка значений W) равна 1.
2) Полигон частот
◄
В статистике исследуют различные совокупности данных — числовых значений случайных величин с учётом частот, с которыми они встречаются в совокупности. При этом совокупность всех данных называют генеральной совокупностью.
Самым распространённым способом статистических наблюдений является выборочное наблюдение. В процессе такого наблюдения изучается только часть генеральной совокупности. Эту часть отбирают специальным методом и называют выборкой.
В статистических исследованиях выборку называют репрезентативной, если в ней присутствуют те и только те значения случайной величины, что и в генеральной совокупности, причём частоты имеющихся в ней данных находятся практически в тех же отношениях, что и в генеральной совокупности.
Центральные тенденции
Совокупность данных иногда бывает полезно охарактеризовать (оценить) одним числом — мерой центральной тенденции числовых значений её элементов. К таким характеристикам относятся мода, медиана и среднее значение.
Мода (обозначают Mo) — это значение случайной величины, имеющее наибольшую частоту в рассматриваемой выборке.
► Например, мода выборки 7, 6, 2, 5, 6, 1 равна 6; выборка 2, 3, 8, 2, 8, 5 имеет две моды:
Mo1 = 2, Mo2 = 8. ◄
Медиана (обозначают Mе) — это число (значение случайной величины), разделяющее упорядоченную выборку на две равные по количеству данных части.
Если в упорядоченной выборке нечётное количество данных, то медиана равна серединному из них. Если в упорядоченной выборке чётное количество данных, то медиана равна среднему арифметическому двух серединных чисел.
► Например, 1) чтобы найти медиану выборки
5, 9, 1, 4, 5, –2, 0,
сначала расположим элементы выборки в порядке возрастания:
–2, 0, 1, 4, 5, 5, 9.
Количество данных нечётно. Слева и справа от числа 4 находятся по три элемента. Значит, 4 — серединное число выборки, поэтому Mе = 4.
2) Рассмотрим уже упорядоченную выборку, состоящую из шести элементов:
1, 2, 3, 4, 6, 7.
Количество данных чётно, серединные данные выборки: 3 и 4, поэтому Mе = (3+4)/2 = 3,5. ◄
Средним значением (или средним арифметическим) выборки называется число, равное отношению суммы всех элементов выборки к их количеству.
Если рассматривается совокупность случайной величины X, то её среднее значение обозначают X.
► Например, найдём среднее значение выборки случайной величины X, если распределение значений по частотам представлено в таблице:
| X | 2 | 3 | 4 | 8 | 10 |
| M | 1 | 2 | 3 | 1 | 1 |
$$\overline{X}=\frac{2\cdot 1+3\cdot 2+4\cdot 3+8\cdot 1+10\cdot 1}{1+2+3+1+1}=\frac{38}{8}=4,75.$$
Ответ: X = 4,75. ◄
Меры разброса
Не каждую выборку имеет смысл оценивать с помощью центральных тенденций (моды, медианы, среднего значения).
► Например, если исследуется выборка 80, 80, 320, 4 600 годовых доходов (в тысячах рублей) четверых человек, то очевидно, что
ни мода Mо = 80,
ни медиана Mе = 200,
ни среднее значение X = 1 270
не могут выступать в роли объективной характеристики данной выборки. Это объясняется тем, что наименьшее значение выборки существенно отличается от наибольшего — разность наибольшего и наименьшего значений (4 520) соизмерима с наибольшим значением. ◄
Размах (обозначается R) — разность между наибольшим и наименьшим значениями случайной величины выборки. Размах показывает, как велик разброс значений случайной величины в выборке.
Отклонением от среднего значения называют разность между рассматриваемым значением случайной величины и средним значением выборки.
► Например, если значение величины X1 = 52, а среднее значение X = 50, то отклонение X1 от среднего значения будет равно
X1 – X =52 – 50= 2. ◄
Отклонение от среднего значения может быть как положительным так и отрицательным числом. Справедливо свойство отклонений от среднего значения:
сумма отклонений всех значений выборки от среднего значения равна нулю:
$$(X_1-\overline{X})+(X_2-\overline{X})~+~...~+~(X_n-\overline{X})=0,$$
где n — количество элементов выборки.
Поэтому характеристикой стабильности элементов выборки может служить сумма квадратов отклонений от среднего значения или среднее арифметическое этих квадратов.
Дисперсия (обозначается D) — это среднее арифметическое квадратов отклонений от среднего значения:$$D=\frac{(X_1-\overline{X})^2+(X_2-\overline{X})^2+...+(X_n-\overline{X})^2}{n}=\frac{1}{n}\sum_{k=1}^{n}(X_k-\overline{X})^2.$$
Для оценки степени отклонения от среднего значения удобно иметь дело с величиной той же размерности, что и сами элементы выборки. С этой целью используют значение корня квадратного из дисперсии \(\sqrt{D}\).
Средним квадратичным отклонением (обозначают σ) называют корень квадратный из дисперсии:$$\sigma =\sqrt{D}=\sqrt{\frac{1}{n}\sum_{k=1}^{n}(X_k-\overline{X})^2}.$$Дисперсию и среднее квадратичное отклонение в статистике называют так же мерами рассеивания значений случайной величины около среднего значения.
► Например, найдём среднее квадратичное отклонение значений выборки:
$$5,~~ 8,~~ 10,~~ 12,~~ 17,~~ 20.$$
1) Находим среднее значение выборки:
$$\overline{X}=\frac{X_1+X_2+X_3+X_4+X_5+X_6}{6}=\frac{5+8+10+12+17+20}{6}=\frac{72}{6}=12.$$
2) Вычисляем отклонения от среднего значения:
$$X_1-\overline{X}=5-12=-7,~\\X_2-\overline{X}=8-12=-4,~\\X_3-\overline{X}=10-12=-2,\\X_4-\overline{X}=12-12=0,~~\\X_5-\overline{X}=17-12=5,~~\\X_6-\overline{X}=20-12=8.~~$$
3) Определяем сумму квадратов отклонений:
$$\sum_{k=1}^{6}(X_k-\overline{X})^2=(-7)^2+(-4)^2+(-2)^2+0^2+5^2+8^2=158.$$
4) Находим дисперсию:
$$D=\frac{1}{6}\sum_{k=1}^{6}(X_k-\overline{X})^2=\frac{1}{6}\cdot 158=26\tfrac{1}{3}.$$
5) Вычисляем среднее квадратичное отклонение:
$$\sigma =\sqrt{D}=\sqrt{26\tfrac{1}{3}}\approx 5,13.$$
Ответ: \(5,13\). ◄
Теорема о средних
Кроме среднего арифметического значения$$\overline{X}=\frac{X_1+ X_2+~...~+ X_n}{n},~~~~X_i\in R$$выборки X1, X2, ... , Xn в некоторых специальных случаях используют и другие средние величины. Вот некоторые из них:
Среднее гармоническое (обозначим H):$$H=\frac{n}{\frac{1}{X_1}+\frac{1}{X_2}+~...~+\frac{1}{X_n}},~~~~~~X_i> 0.$$
Среднее геометрическое (обозначим G):$$G=\sqrt[n]{X_1\cdot X_2\cdot ~...~\cdot X_n},~~~~~~X_i> 0.$$
Среднее квадратическое (квадратичное) (обозначим Q):$$Q=\sqrt{\frac{X_1^2+ X_2^2+~...~+ X_n^2}{n}},~~~~X_i\in R.$$
Теорема о средних. Любые положительные числа X1, X2, ... , Xn удовлетворяют неравенствам:$$\min \left \{X_1,X_2,~...~, X_n \right \}\leq H\leq G\leq \overline{X}\leq Q\leq\max \left \{X_1,X_2,~...~, X_n \right \},$$причём если среди этих чисел найдутся хотя бы два различных, то все неравенства строгие.
Смотрите так же:
Арифметический корень n-й степени
Построение графиков функций геометрическими методами
Арифметическая и геометрическая прогрессии
Таблицы значений тригонометрических функций
Предел и непрерывность функции
![]()
Создано на конструкторе сайтов Okis при поддержке Flexsmm - накрутка подписчиков телеграм